
DC is for Data-Contract
Data-contracts are representations of parts of the abstract model suitable to transit across service boundaries; typically to and from clients of services.
Below are some guidelines to delineate the two similar concepts of models and data-contracts, both of which find themselves expressed in data-schema and structures, serialized for communication or storage, and referenced in code.
Model Representation
- Principal Aim: Abstractions represented as code or data-structures
- Scope: Expansive
- References: Cyclic/Comprehensive
- Home Turf: Process Space (Memory or RDBMS)
- Persistence: Most Likely
- Access: System-Level
- Responsibilities: Integrity, State, Lifetime
Data-Contract Representation
- Principal Aim: Engineering glue for inter process-communication
- Scope: Narrow/Fragmentary
- References: Tree-Like/Sparse
- Home Turf: Serialized Stream
- Persistence: Transient
- Access: Focused to task or caller
- Responsibilities: Communication, Inputs, Outputs
Data Topology
In model representations that are projected into memory graphs or into an RDBMS, closed loop-like structures are fairly common and sometimes desirable as they can ease tracing back relations bi-directionally between model elements. As useful as it is for every object collection to know it’s contents, it can be equally useful for every element in the collection to know the collections it is contained in.
In data-contracts, memory-graph is less important than the serialization stream. Data-contracts main use is to package model state for transit across service (typically runtime) boundaries. Relations and references usually go one way (i.e., root to branches).
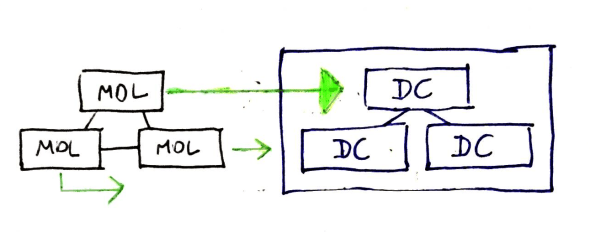
- Data-Contracts are more tree-like and less loopy
Serializability
Since a data-contract can cross a service boundary, it can also cross a runtime boundary. Crossing a runtime boundary requires a representation of the data-contract to be projected into another runtime instance. To be projected, it needs to be transmitted; to be transmitted, it needs to be “flattened” into a linear stream of bytes. This crossing can be symmetric, with a service both sending data-contract information outbound and accepting data-contract information inbound.
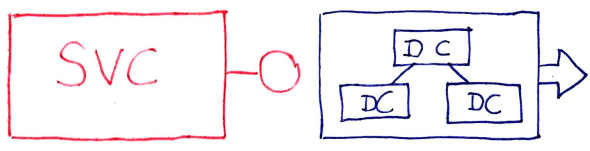
Data-Contracts Outbound
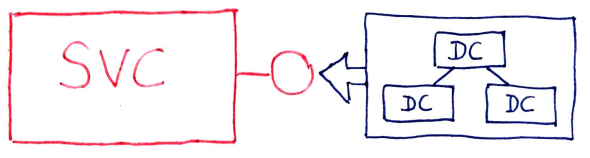
Data-Contracts Inbound
Serialization is a narrowing of data-structure to a serial stream of bytes. A stream of bytes requires communication-time and resource to transit. In the transiting operation there is also formatting and encoding occurring during the creation of the stream, and corresponding decoding and reconstruction of the data-contract’s object graph into the target runtime environment. The smaller the data-contract object graph size, the smaller the serialization stream, the faster the transit, the quicker to process.
While many modern serialization engines can take an object graph with closed loop-like structures and project it into a serialization stream that allows placeholders and multi-pass fixups to resolve circular references; the results can lead to large (unintended) serialization streams being produced for relatively small amounts of data, as back references are followed and projected.
Consequently, small tightly-delineated data-contract schemas are preferable. It is possible to define larger more expansively connected data-contract schemas, and only partially fill or expand their references under certain circumstances, but this can lead to some confusion on why a data-contract is sparsely filled; that is, is the contract instance sparsely filled to save processing and transmission time? or is it sparsely filled because the model elements they represent lack reference to other objects…?
Lookups and Resources
One goal of data-contract design is to keep the serialization stream small as it consumes communication bandwidth (as well as encoding/decoding processing time) when transmitting between runtimes. Isolating frequently referenced, infrequently changing and commonly related information into their own mini-systems of data-contracts and service operations helps accomplish this by separating stable, bulky and commonly referenced model elements from volatile context dependent data-streams.
Within Ikosa, graphical resources (images, models and icons) and geographical features (room structure, geographic cell structure) count as data that is relatively bulky, frequently referenced and stable. Correspondingly, entire room definitions are expected to be “looked up” using the appropriate service call when referenced in a response from the server.
A client getting information about what rooms a player character can see gets a list of room identifiers, not the entire structure of each room. If the client doesn’t have a copy of the room structure (or it it’s out of date), it can call another service to get the rest of the data. The same is true for the structure of the room geometries in each cell, and for the resources used to “paint” walls, floors and ceilings.
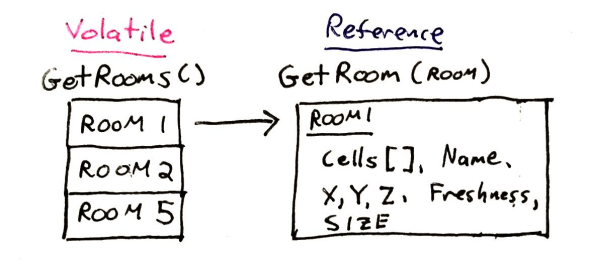
currently visible rooms are volatile, whereas any room definition is relatively stable
Identity
The caching and lookup aspects described above supported by the condition that nearly every data-contract type has some “key” data-member or group of members that uniquely identify it in its use context. Rooms have identifiers, graphic resources have names, cell types have palette indexes.
Not only is this useful for lookups and references, but also when sending back aiming or selection information, a client can forgo filling out an entire data-contract sometimes and only supply the key values referencing the model element(s) specified. If a list of potential actions or targets has to be selected on the client, the client doesn’t have to send the entire data-contract to signal it’s intention, only the action provider’s ID and the action key; or the target key; whereas the service may have provided significantly more information to present the options to the client.
Ikosa does have some “description” contract types that provide messages or notifications. These don’t represent model elements, selectable choices nor resources, and therefore they lack any sense of durable identity.
Service Support Patterns
The Ikosa framework largely defines data-contract assemblies as independently buildable code units (the visualization assembly includes both data-contract and functional models together, but this is largely historic and would need to be refactored to replace the WPF presentation framework at a later date). This independence provides flexibility in where to write code for converting models to and from data-contracts.
One obvious place to perform this is in service code. As services present the interfaces that consume and supply data-contracts they are a natural junction between the two representations of information abstractions. This is why I place the letters in MSDCPVMUI in the order I do. “S” for service sits between “M” for model and “DC” for data-contract.
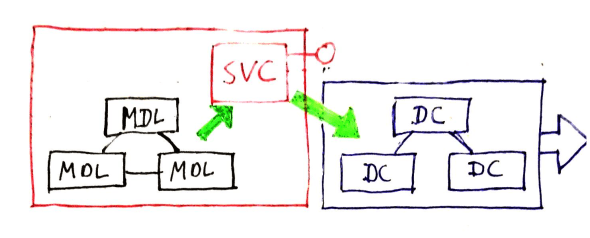
service code converting models to data-contracts
Service interfaces can express data-contracts of a specific type, but might actually provide or consume data-contract instances of derived types. The service contract defining the interface needs to have some way declare type-hierarchies not expressed in the service interface, but compatible with the service operations. In WCF this is handled by KnownTypes which helps extend service meta-data to define additional type information.
- Note: known-types only applies to service implementation infrastructures that support strong type-systems. Ikosa is such a system, but many services that (exclusively or otherwise) support JavaScript/JSON object representations do not need type descriptions. Instead they rely on language/runtime features that support string-bound “late” binding of data members to code constructs.
In addition to the conversion of data-contracts, service operations may be defined supporting lookup and load functions for common reference types and resources.
Services may also convert inbound data-contracts to model references (reversing the outbound conversion), and therefore they need access to the model space.
Model Support for Data-Contracts
Services may not necessarily be alone in handling data-contracts for models. A model system representation might be truly independent from the data-contract definitions, in which case the service code must do the heavy lifting to present the model as data-contracts and convert back when needed. Ikosa, however, defines the model assemblies as dependent on the data-contract assemblies, allowing model code to take a more active role in data-contract processing.
One common processing function is the generation of data-contracts for outbound service interface operations from the model via specialized method on those models.
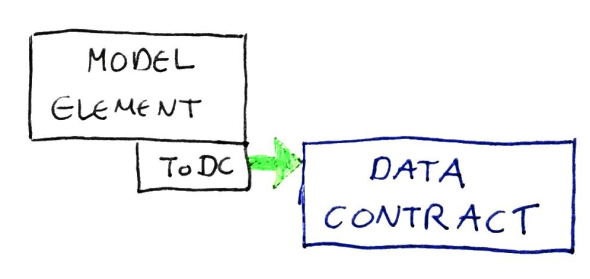
Model.ToDataContract()
In addition to outbound conversion, a model may help convert inbound data-contract representations from the service interface. In Ikosa, this is especially true with the selection of aiming targets from aiming target data-contracts. When a client selects an aim target data-contract in the user-interface, its representation (and the action’s representation) is transmitted to the service. The model for the action being generated is responsible for handling the conversion (with additional help from the Aiming Modes defined by the action):
public virtual IEnumerable ConvertTargets(
CoreActor actor, AimTargetInfo[] targets, IInteractProvider provider)
{
var _activity = new CoreActivity(actor, this, null);
return from _aim in AimingMode(_activity)
from _target in _aim.GetTargets(actor, this, targets, provider)
select _target;
}
Also, a model may store some of its state as data-contract objects, effectively blurring the implementation lines between model elements and data-contract elements. In Ikosa, descriptive information is stored in data-contract form and keyed to “information IDs”. Depending on the character requesting information about an item, different information may be returned. Rather than store this in some intermediate “pure-model” form and work the conversion on each call, the native format is a data-contract instead.
Self-Supplied Support
As a .NET class, a data-contract objects can have additional methods that are not part of the serialization graph. Even though these non-serializing class members might be used in supporting services, or supporting client operations; it’s usually good to keep their scope narrow, so they operate only on the state of the data-contract. In other words, they should really support the data-contract itself and should not rely on specific service or client system code.
For example, in the visualization system the CubicInfo data-contract has functions for determining whether a location is inside the cubic extent (amongst others). It uses state information serialized in the data-contract stream to accomplish this. These types of functions might be considered part of model operations if used on the service-side of things, or part of the “view-model” is used on the client-side of things (more on that later).
[DataMember]
public int Z { get; set; }
[DataMember]
public int Y { get; set; }
[DataMember]
public int X { get; set; }
[DataMember]
public int ZTop { get; set; }
[DataMember]
public int YTop { get; set; }
[DataMember]
public int XTop { get; set; }
public bool ContainsCell(int z, int y, int x)
=> (z >= Z) && (y >= Y) && (x >= X)
&& (z <= ZTop) && (y <= YTop) && (x <= XTop);
